범주형 데이터 인코딩
머신러닝을 위해 범주형 문자열 데이터를 숫자(코드)로 변환
대표적 인코딩 방식
- Label Encoding: 범주형 변수를 코드형 숫자값으로 변환. 변환된 숫자의 크기는 의미가 없어, 숫자의 크기가 중요한 회귀분석에서는 사용하지 않는다. 크기에 영향을 받지 않는 분류 분석에 사용한다
from sklearn.preprocessing import LabelEncoder
import numpy as np
items=['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '믹서', '믹서']
encoder = LabelEncoder()
labels = encoder.fit_transform(items)
print(labels)
print(encoder.classes_)
print(encoder.inverse_transform(labels))
- One Hot Encoding: 변수값의 종류수(Cardinality)만큼의 비트bit를 할당하고 변수값 별로 서로 다른 비트를 부여
from sklearn.preprocessing import OneHotEncoder
oh_encoder = OneHotEncoder()
labels = labels.reshape(-1,1) # 열이 하나인 2차원 배열 구조로 변환
oh_labels = oh_encoder.fit_transform(labels)
print(oh_labels)
print(oh_labels.toarray()) # 2차원 배열로 전환
예시) Cardinality가 8인 경우
- Label Encoding: [0, 1, 2, 3, 4, 5, 6, 7], bit로 변환시 001, 001, 010, 011, ..., 111: 8개(2^3)
- One Hot Encoding: bit로 변환시 10000000, 01000000, ... : 8개
데이터 불균형 문제 해결
부류학습에서 종속변수의 각 클래스에 속한 데이터 개수가 현저히 차이가 난 상태로(bias) 모델을 학습하면, 다수의 클래스로 분류를 많이하게 되는 문제가 생기고 모델의 성능을 감소시킨다.
해결법
- 언더샘플링: 데이터개수가 많은 클래스를 적은 클래스 수준으로 감소하는 방식
- 오버샘플링: 데이터개수가 적은 클래스를 많은 클래스 수준으로 증가하는 방식
언더샘플링은 학습에 사용되는 전체 데이터 수를 급격히 감소시켜 성능을 낮출 가능성이 있어 언더샘플링보다는 오버샘플링을 선호한다.
SMOTE
대표적인 오버샘플링 기법으로, 낮은 비율 클래스 데이터에 대해 완전히 똑같은 특성값을 가진 데이터를 생성하는 것이 아니라 최근접 이웃을 이용하여 새로운 데이터를 생성한다
분류 성능 평가 지표 Classification Performance Estimation Index
분류모델의 예측력을 검증/평가하는 지표
| 실제 | |||
| 예측 | Positive | Negative | |
| Positive | True Positive | False Positive | |
| Negative | False Negative | True Negative | |
- 정확도 Accuracy: (TP + TN) / (TP + TN + FP + FN) 전체 예측 건수 중 정답을 맞힌 건수의 비율. 클래스 간의 불균형이 심할 경우, 정확도가 항상 높게 유지되는 Accuracy Paradox가 발생한다
- 정밀도 Precision: TP / (TP + FP) 분류모델이 True라고 예측한 것들 중 실제 정답이 True인 비율. 실제 정답의 대부분이 True일 경우 항상 높은 정밀도를 유지하는 왜곡이 발생할 수 있다
- 재현율 Recall: TP / (TP + FN) 실제로 정답이 True인 것들 중 분류모델이 True로 예측한 비율. 모두 True로 예측하는 분류모델에서 항상 recall 값이 1이 되는 성능 왜곡이 발생할 수 있다
- F1-score: 2 * (Precision * Recall) / (Precision + Recall) 서로 상반된 성격을 가진 정밀도와 재현율 두 지표를 균형있게 함께 반영하여 만든 조화평균 지표. 정밀도와 재현율 지표값의 편차가 심할수록 F1-score는 산술평균에 비해 낮게 나오므로, 분류모델의 성능을 보다 현실감있게 산출 가능
실습: SMOTE
1. 필요한 데이터 불러오고 시각화하기, 데이터 쪼개기
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
import pandas as pd
df = pd.read_csv('datasets/creditcard.csv')
df.Class.value_counts(normalize=True).plot(kind='bar')
print(df.Class.value_counts(normalize=True)*100)
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.25,random_state=10)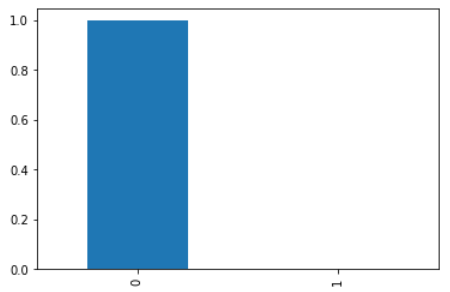
2. 데이터 SMOTE
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=0)
X_over,y_over = smote.fit_sample(X,y)
print('SMOTE 적용 전 학습용 피처/레이블 데이터 세트: ', X.shape, y.shape) #(284807, 30) (284807,)
print('SMOTE 적용 후 학습용 피처/레이블 데이터 세트: ', X_over.shape, y_over.shape) #(568630, 30) (568630,)
print('SMOTE 적용 후 레이블 값 분포: \n', pd.Series(y_over).value_counts()) # 1 284315 0 284315
X_train_over, X_test_over, y_train_over, y_test_over = train_test_split(X_over, y_over, test_size=0.25, random_state=10)
3. 모델링 및 학습/검증 함수와 분류 성능평가 지표 함수 생성
def f_model_fit(cls, model,X_train,X_test,y_train,y_test):
model.fit(X_train,y_train)
pred = model.predict(X_test)
f_metrics(cls, y_test,pred)
def f_metrics(cls, y_test,pred):
accuracy = accuracy_score(y_test,pred)
precision = precision_score(y_test,pred)
recall = recall_score(y_test,pred)
f1 = f1_score(y_test,pred)
print(cls + '정확도 : {0:.3f}, 정밀도 : {1:.3f}, 재현율 : {2:.3f}, f1-score : {3:.3f}'.format(accuracy, precision, recall, f1))
4. Logistic Regression
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
lr = LogisticRegression()
%time f_model_fit('Logistic Regression(SMOTE적용 전) -> ', lr, X_train, X_test, y_train, y_test)
%time f_model_fit('Logistic Regression(SMOTE적용 후) -> ', lr, X_train_over, X_test_over, y_train_over, y_test_over)
# 모델 성능 평가: Confusion Matrix array([[69889, 1201],[2551, 68517]], dtype=int64)
y_hat_over = lr.predict(X_test_over)
lr_matrix = metrics.confusion_matrix(y_test_over, y_hat_over)
lr_matrix
# 모델 성능 평가: 평가 지표 계산
lr_report = metrics.classification_report(y_test_over, y_hat_over)
print(lr_report)

5. 결정트리
from sklearn.tree import DecisionTreeClassifier
decision_tree = DecisionTreeClassifier(criterion='entropy', max_depth=4, random_state=0)
%time f_model_fit('Decision_tree(SMOTE적용 전) -> ', decision_tree, X_train, X_test, y_train, y_test)
%time f_model_fit('Decision_tree(SMOTE적용 후) -> ', decision_tree, X_train_over, X_test_over, y_train_over, y_test_over)
y_hat_over = decision_tree.predict(X_test_over)
decision_tree_matrix = metrics.confusion_matrix(y_test_over, y_hat_over)
decision_tree_matrix #array([[69829, 1261],[3855, 67213]], dtype=int64)
decision_tree_report = metrics.classification_report(y_test_over, y_hat_over)
print(decision_tree_report)

6. 랜덤포레스트
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(n_estimators=20, random_state=0)
%time f_model_fit('Random_forest(SMOTE적용 전) -> ', random_forest, X_train, X_test, y_train, y_test)
%time f_model_fit('Random_forest(SMOTE적용 후) -> ', random_forest, X_train_over, X_test_over, y_train_over, y_test_over)
y_hat_over = random_forest.predict(X_test_over)
random_forest_matrix = metrics.confusion_matrix(y_test_over, y_hat_over)
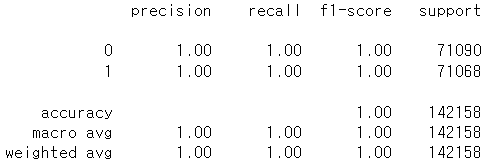
random_forest_matrix # array([[71077, 13], [3, 71065]], dtype=int64)
random_forest_report = metrics.classification_report(y_test_over, y_hat_over)
print(random_forest_report)

7. XGBoost
import xgboost as xgb# xgboost 기법에 관련된 모듈
gbm = xgb.XGBClassifier(max_depth=4, n_estimators=300, learning_rate=0.05, eval_metric='logloss')
%time f_model_fit('XGBoost(SMOTE적용 전) -> ', gbm, X_train, X_test, y_train, y_test)
%time f_model_fit('XGBoost(SMOTE적용 후) -> ', gbm, X_train_over, X_test_over, y_train_over, y_test_over)
y_hat_over = gbm.predict(X_test_over)
gbm_matrix = metrics.confusion_matrix(y_test_over, y_hat_over)
gbm_matrix #array([[70912, 178],[200, 70868]], dtype=int64)
gbm_report = metrics.classification_report(y_test_over, y_hat_over)
print(gbm_report)

8. LightGBM
from lightgbm import LGBMClassifier
lgb = LGBMClassifier(n_estimators=1000,num_leaves=64,n_jobs=-1,boost_from_average=False)
%time f_model_fit('Lightgbm(SMOTE적용 전) -> ', lgb, X_train, X_test, y_train, y_test)
%time f_model_fit('Lightgbm(SMOTE적용 후) -> ', lgb, X_train_over, X_test_over, y_train_over, y_test_over)
y_hat_over = lgb.predict(X_test_over)
lgb = metrics.confusion_matrix(y_test_over, y_hat_over)
lgb #array([[71074, 16],[0, 71068]], dtype=int64)
lgb_report = metrics.classification_report(y_test_over, y_hat_over)
print(lgb_report)
'데이터 청년 캠퍼스 > 전처리' 카테고리의 다른 글
| [전처리] 고급 SQL 이해와 활용(1) (0) | 2022.07.21 |
|---|---|
| [전처리] 주성분분석 (0) | 2022.07.21 |
| [전처리] 데이터 통합, 상관 분석, 데이터 축소, 속성부분 집합 선택 (0) | 2022.07.19 |
| [전처리] 데이터 전처리 개요, 결측값 해결 (0) | 2022.07.19 |

